Obfusware is designed to run efficiently and simply within AWS Glue, making it ideal for use with Big Data. Developed by engineers who were dissatisfied with the slow speeds, complicated setups, and the high licensing costs of older solutions, Obfusware addresses these challenges directly. As organizations increasingly rely on data masking to meet strict security and privacy standards, Obfusware offers a high-performance, user-friendly solution. Whether you're migrating systems to the cloud, working in a fast-paced CI/CD environment, or using proprietary data to train an LLM, Obfusware serves as your go-to data masking tool on AWS.
Designed to work within AWS Glue.
Leverages all the inherent features of AWS Glue, including accessing all data sources
Familiar environment, easy to integrate workflows, quick to deploy for practical use.
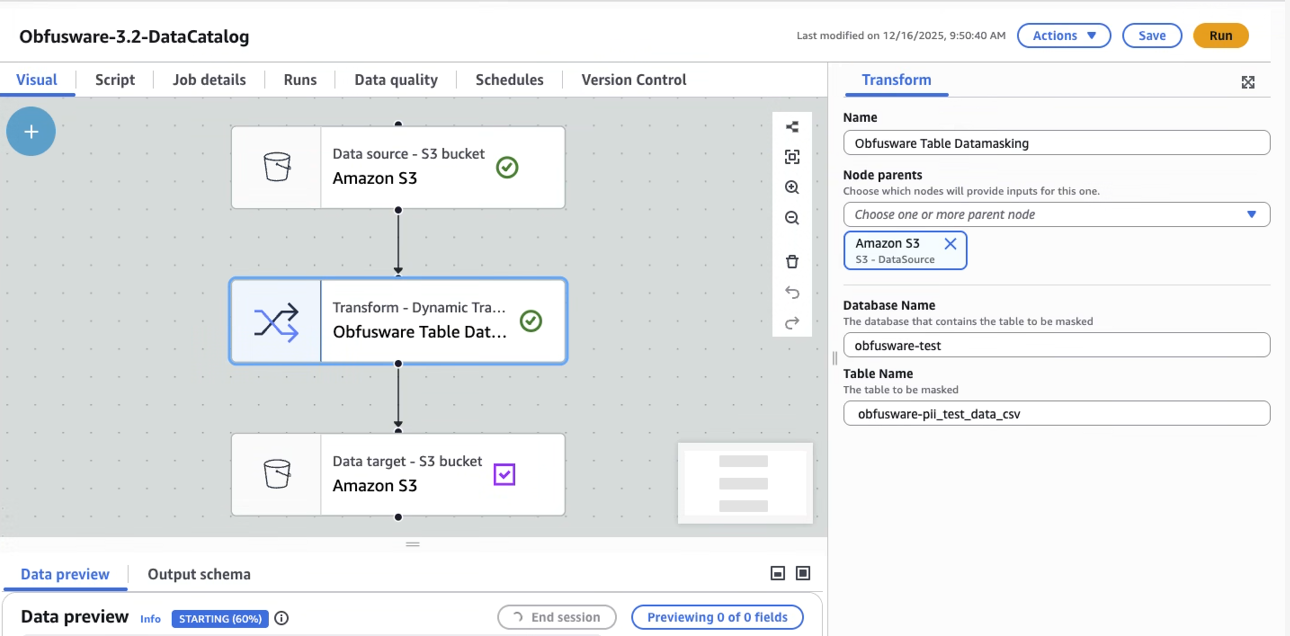
Integrates with Glue Data Catalog.
Leverages the CVT interface to allow data pipelines to be developed using Glue Studio.
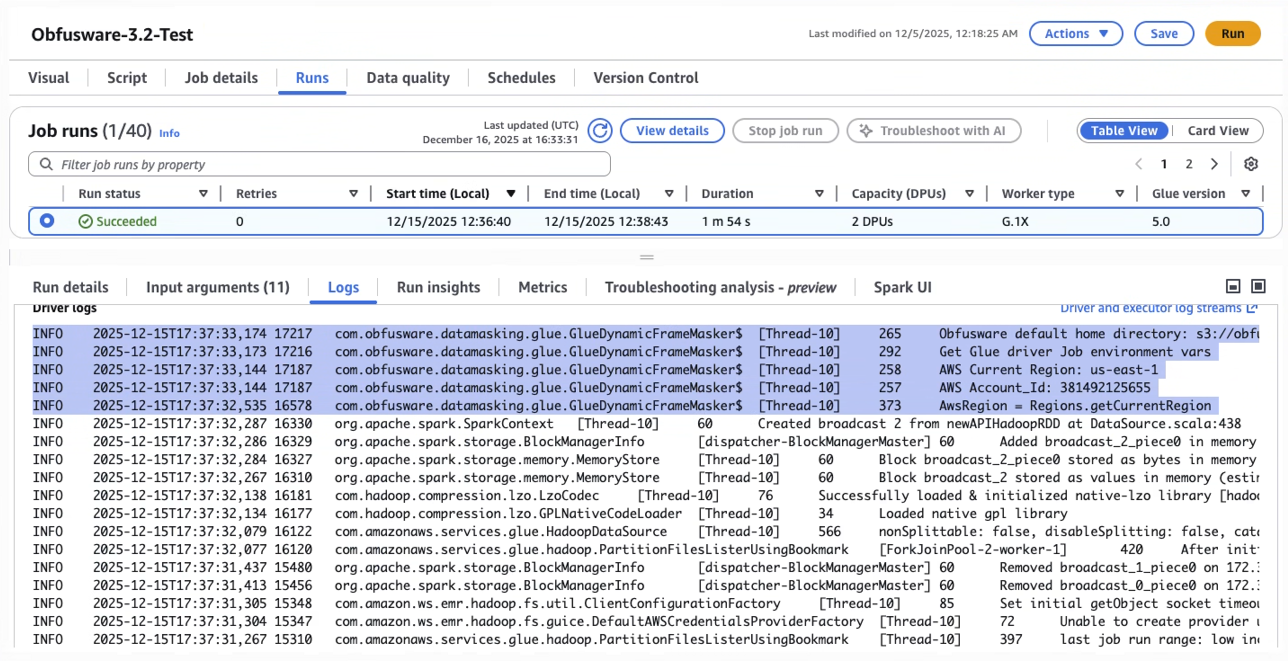
Code executes in native Glue environments.
Code can be observed in standard AWS run logs.
The rush to agentic AI is real. Companies in every industry are racing to capitalize on its promise. One recognized challenge is preventing the disclosure of private information. Because AI is trained on large volumes of data and that data becomes encoded in the AI model, any data used to train the model can become part of answers provided by the AI when prompted, exposing private data.
The solution is to mask private data prior to training the model while preserving the realism of the information. Obfusware masks data and replaces it with realistic data that maintains the data realism, relationships and referential integrity required to train AI models while preserving customer and business data privacy, and providing regulatory compliance risk management.
Obfusware has been designed with advanced data masking features and capabilities for maximum performance

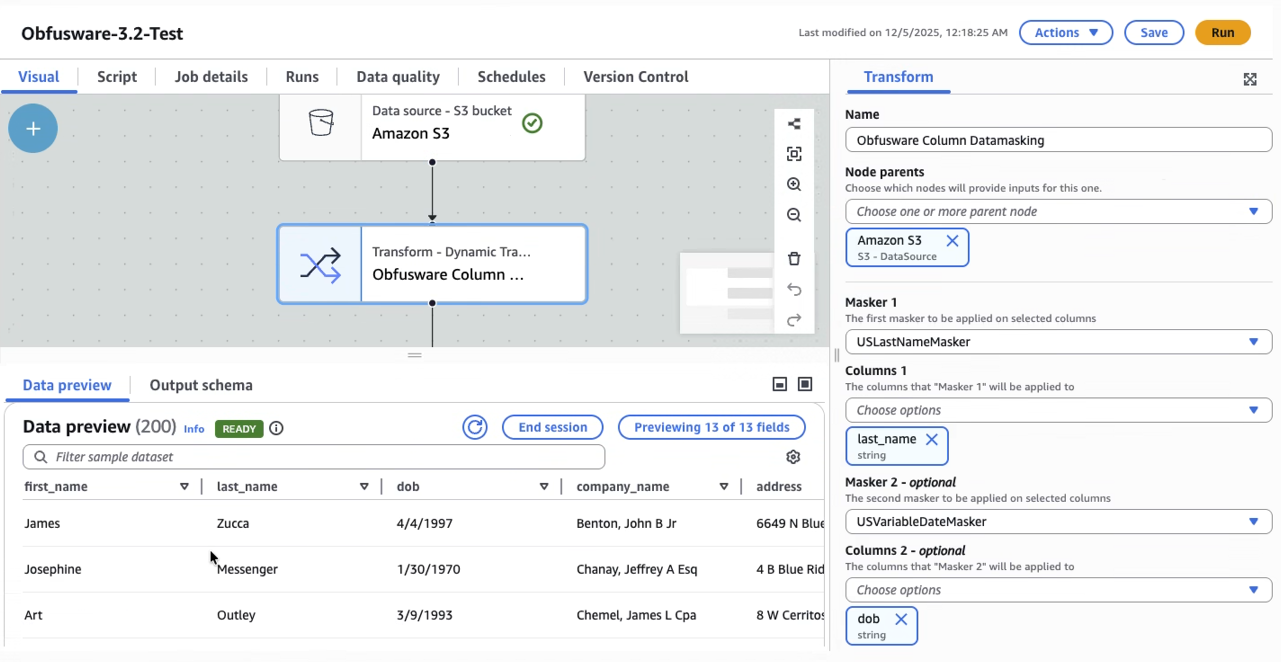
Obfusware provides an extensive set of data masking or obfuscation functions based on proven algorithms
Maintaining data referential integrity is one of the key characteristics of useful data masking algorithms
Data does not exist in isolation. It most often is related to other data items or even very often duplicated. When masking data it is critical to maintain referential integrity. If a data value is masked in one data table or file, then it is important that it is masked in any other table or file to the same value. This means data masking methods need to be deterministic, always returning the same masked value for a given input value.
Enables data consistency for related or dependent fields when masked
Often there are dependencies and relationships between fields. A simple example is the relationship between the State and the Zipcode fields an address. Zipcodes are strongly related to states. All New Hampshire zipcodes start with the digit 03, while New York zipcode start with the digits 10,11,12,13, or 14. If a persons sees an address with New Hampshire 12543, it does not make sense. If there is data validation code it may reject or throw an error. Obfusware has the ability to use a key field for masking. If two fields use specify the same key field, then the data relationship or dependency can be maintained even in the masked field values. This is essential for AI LLM training.
Big Data is often includes semi-structured and structured data
Data formats often used with Big Data such as Parquet, JSON, and XML are charactered as semi-structured because the do not conform to the strict requirements of structured data used by RDBMS. Semi-structured data is often self-describing, including tags to describe fields instead of conforming to a set schema. Semi-structured data is often nested and each data element may contain different fields.
Obfusware provides support for semi-structured nested data by allowing addressing of nested fields using JSON like field selectors (ie "object.field1.subfield"). This alleviates the need to transform the data using techniques such as flattening to efficiently apply data masking, and the potential loss of data structure and information during transformations, while delivering high performance.
It is important that data masking not return the same results for every organization
One of the requirements of data masking is that it should be impossible to determine the original data value from the masked value. If data masking methods return the same value for for every organization, then it would be possible to a third party to use the software to determine what original values mask to a given result value. This would allow them to potentially determine the original value thus invalidating the privacy promised by data masking.
Obfusware creates a unique context for each organization using the data masking software. Using cryptographic techniques, the context is used to generate a unique mapping from the original data value to the masked data value. The result is deterministic so the masking for a given organizational context will not change overtime.
Obfusware data maskers offer many configuration options to produce varied results to meet requirements
Obfusware offers over a dozen data masking algorithms, each of which can be configured to create numerous data maskers to meet specific criteria. Out-of-the-box, Obfusware offers almost two dozen pre-configured maskers to meet a the most common data masking requirements.
Extend Obfusware data masking with customer data maskers using the Obfusware masker API
While Obfusware built-in data masking algorithms cover the vast majority of data masking requirements there are situations when an organization's custom requirements cannot be met using standard masking algorithms. For these cases, Obfusware provides the ability to add custom data masking algorithms using the masker API. It's as simple as writing Java with a few methods implementing the desired behavior.
Obfusware provides extensive configurable statics gathering on masking operations
Obfusware gathers statistics on the time spent masking data including count, min, max, mean, variance, and standard deviation, throughput and error rates. Obfusware is able to aggregate statistics from distributed operations to provide an overview of masking performance (see Apache Spark).
High performance data masking to manage your compliance risk. Provides the Big Data tools support to seamlessly integrate with your enterprise Data Lake for AI model training.
purchase obfusware